
谷歌外贸站SEO指南,搜索引擎是如何工作的
本文有972个文字,大小约为5KB,预计阅读时间3分钟
原文标题:谷歌外贸站SEO指南,搜索引擎是如何工作的
搜索引擎是如何工作的?
在之前的文章中,我们介绍了SEO的基本概念
并提到它主要是针对搜索引擎进行优化。
那么,什么是搜索引擎?它是如何工作的呢?今天,我们了解下搜索引擎的基本运作原理。
什么是搜索引擎?
简单来说,搜索引擎是一种在线查找工具,帮助我们在互联网上找到想要的信息。
提到搜索引擎,大家可能首先想到的是谷歌(Google)。
谷歌(Google)在全球搜索引擎市场中占据了很大的份额,可以说是最受欢迎的搜索引擎之一。

但是,除了谷歌,市面上还有很多其他的搜索引擎,但它们的工作原理大致相同。
搜索引擎如何工作?
要提升网站在搜索引擎中的排名,首先要了解搜索引擎是如何工作的?
每个搜索引擎都有自己独特的算法,我们以谷歌为例,了解它的工作机制。
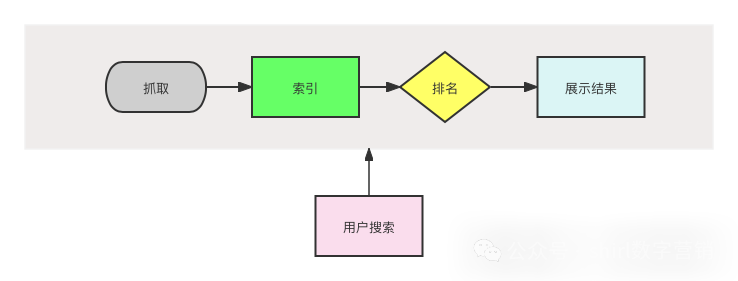
谷歌(Google)的搜索引擎工作流程可以分为三个主要步骤:
1. 抓取
首先,谷歌需要找到互联网上的网页。
由于网络上没有统一的网页目录,谷歌需要通过两种方式来发现新网页:
链接发现:如果一个网页被其他网页链接,谷歌就可以顺着这些链接找到新的页面。
网站主动提交:网站管理员可以通过提交网站地图,告诉谷歌哪些网页需要被抓取。
一旦谷歌发现了网页,它就会派出Googlebot(也叫爬虫或蜘蛛)来访问这些页面。
爬虫就像一个网页阅读器,能够读取并解析网页内容。
不过,要注意在抓取过程中,Googlebot有时会遇到一些问题,导致我们的网页无法被抓取。
比如
- 我们的网站服务器可能出现故障
- 我们的网络连接可能不稳
- 或者网站设置了访问限制
这就是谷歌(Google)如何发现和了解网页内容的第一步。
2. 索引
抓取网页后,谷歌(Google)会对网页进行分析,理解页面的内容。这一过程称为索引。
谷歌(Google)会读取网页的标题、正文、图片、视频等信息,并处理网页上的关键词和其他重要元素。
同时,谷歌(Google)还会记录很多关于网页的信息,比如:
这个网页是用什么语言写的 是针对哪个国家或地区的用户 网页在不同设备上是否好用
这些收集到的信息会被存储在谷歌(Google)的大型数据库中。
但并不是所有的网页都会被索引,以下情况可能导致我们的网页被排除在外:
- 内容质量较差;
- 网站明确标明不希望被索引;
- 网站设计问题,导致谷歌无法理解页面内容。
简单来说,这个阶段就是谷歌(Google)在理解和整理它找到的网页内容,为之后能在搜索结果中展示这些内容做准备。
3. 呈现搜索结果
当我们或者用户在搜索框输入内容时,谷歌(Google)会根据很多因素来决定向我们展示什么结果:
会考虑我们在哪里搜索 用的是什么语言 是用手机还是电脑在搜索
比如说,同样搜索"自行车维修店",在北京和在广州看到的结果肯定是不一样的。

搜索结果的展示方式也会根据搜索内容的不同而改变。有时候会显示地图,有时候会显示图片,这都取决于谷歌(Google)判断什么样的展示方式最适合我们的搜索需求。
有时候一个网页虽然已经被Google收录了,但在搜索结果中却看不到,主要有这么几个原因:
- 这个网页的内容跟搜索的内容不相关
- 网页内容质量不够好
- 网站设置了不允许展示的规则
总的来说, 这个过程是自动的,也是动态变化的,目的是为了给用户提供最好的搜索体验。
总结一下,Google的工作过程就是这样:
先抓取网页,再对网页进行索引,然后根据我们的搜索请求选出最相关的结果展示给我们。
到这里,大家可能会有一个疑问:
为什么有些网页能排在搜索结果的前面,而有些网页却排在后面,甚至在多个搜索结果页之外呢?
下篇我们将详细介绍谷歌的排名机制,了解搜索引擎如何评估网页并决定排名。
本文参考资料:https://developers.google.com/search/docs/fundamentals/how-search-works
本文来源:https://google520.net/seo/275.html
版权声明:本文为向前网络工作室,未经站长允许不得转载。
 获得更多外贸订单
获得更多外贸订单